Распределение Пуассона
Функция массы вероятности 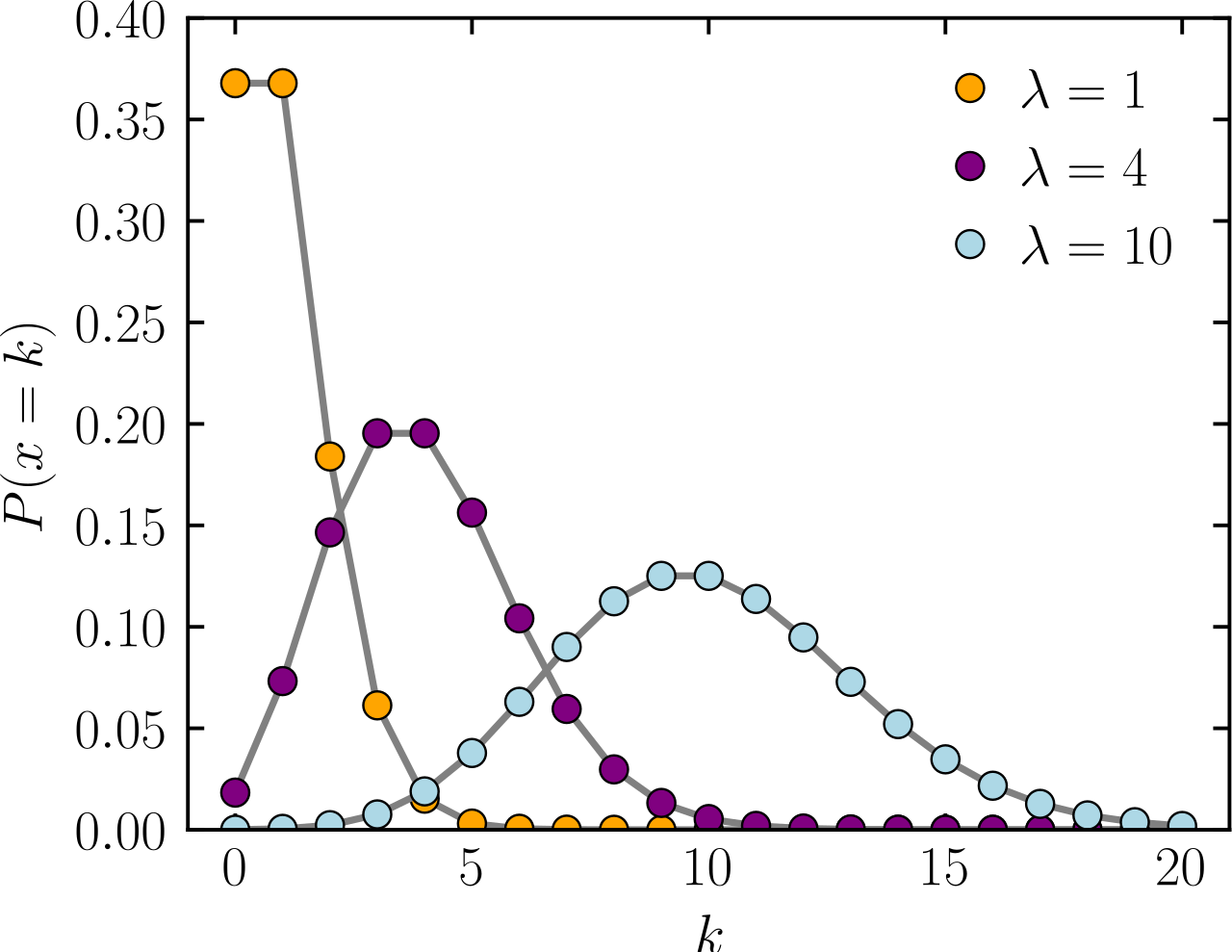 Горизонтальная ось — индекс k , количество появлений. λ — ожидаемая частота появлений. Вертикальная ось — вероятность k появлений при заданном λ . Функция определена только при целых значениях k ; соединительные линии служат лишь ориентирами для глаза. | |||
Кумулятивная функция распределения  Горизонтальная ось — это индекс k , количество вхождений. CDF разрывна в целых числах k и плоская везде, поскольку переменная, распределенная по закону Пуассона, принимает только целые значения. | |||
| Обозначение | |||
|---|---|---|---|
| Параметры | (ставка) | ||
| Поддерживать | ( Натуральные числа, начиная с 0) | ||
| ПМФ | |||
| СДФ | или или ( где — верхняя неполная гамма-функция , — нижняя функция , а — регуляризованная гамма-функция ) | ||
| Иметь в виду | |||
| Медиана | |||
| Режим | |||
| Дисперсия | |||
| Асимметрия | |||
| Избыточный эксцесс | |||
| Энтропия | или для больших | ||
| МГФ | |||
| CF | |||
| ПГФ | |||
| Информация о Фишере | |||
















![{\displaystyle \lambda {\Bigl [}1-\log(\lambda ){\Bigr ]}+e^{-\lambda }\sum _{k=0}^{\infty }{\frac {\lambda ^{k}\log(k!)}{k!}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/64c5bb5a142a1b60e4a04c725d686557fdb238bc)

![{\displaystyle \exp \left[\lambda \left(e^{t}-1\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/72c1560d02e57d6d1f2a6223fa16061ad399bb3a)
![{\displaystyle \exp \left[\lambda \left(e^{it}-1\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f2d912f7d931127ba7a6d044105a647ea4590b40)
![{\displaystyle \exp \left[\lambda \left(z-1\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b112607a91ffced05b02706979ee6651a6db3c84)
В теории вероятностей и статистике распределение Пуассона ( / ˈ p w ɑː s ɒ n / ) — это дискретное распределение вероятностей , которое выражает вероятность заданного числа событий, происходящих в фиксированном интервале времени, если эти события происходят с известной постоянной средней скоростью и независимо от времени, прошедшего с момента последнего события. [1] Его также можно использовать для числа событий в других типах интервалов, отличных от времени, и в размерности больше 1 (например, число событий в заданной области или объеме).
Распределение Пуассона названо в честь французского математика Симеона Дени Пуассона . Оно играет важную роль для дискретно-устойчивых распределений .
При распределении Пуассона с ожиданием λ событий в заданном интервале вероятность k событий в том же интервале равна: [2] : 60

Например, рассмотрим колл-центр, который получает в среднем λ = 3 звонка в минуту в любое время дня. Если звонки независимы, получение одного звонка не изменяет вероятность того, когда поступит следующий. При этих предположениях число звонков k , полученных в течение любой минуты, имеет распределение вероятности Пуассона. Получение k = от 1 до 4 звонков имеет вероятность около 0,77, в то время как получение 0 или по крайней мере 5 звонков имеет вероятность около 0,23.
Классическим примером, используемым для обоснования распределения Пуассона, является число событий радиоактивного распада в течение фиксированного периода наблюдения. [3]
История
Распределение было впервые введено Симеоном Дени Пуассоном (1781–1840) и опубликовано вместе с его теорией вероятностей в его работе Recherches sur la probabilité des jugements en matière criminelle et en matière civile (1837). [4] : 205-207 Работа теоретизировала о количестве неправомерных осуждений в данной стране, сосредоточившись на определенных случайных величинах N , которые подсчитывают, среди прочего, количество дискретных событий (иногда называемых «событиями» или «прибытиями»), которые происходят в течение временного интервала заданной длины. Результат уже был дан в 1711 году Авраамом де Муавром в De Mensura Sortis seu; de Probabilitate Eventuum in Ludis a Casu Fortuito Pendentibus . [5] : 219 [6] : 14-15 [7] : 193 [8] : 157 Это делает его примером закона Стиглера и побудило некоторых авторов утверждать, что распределение Пуассона должно носить имя Муавра. [9] [10]
В 1860 году Саймон Ньюкомб подогнал распределение Пуассона к числу звезд, обнаруженных в единице пространства. [11] Дальнейшее практическое применение было сделано Ладиславом Борткевичем в 1898 году. Борткевич показал, что частота, с которой солдаты прусской армии случайно погибали от ударов лошади, может быть хорошо смоделирована с помощью распределения Пуассона. [12] : 23-25 .
Определения
Функция массы вероятности
Говорят, что дискретная случайная величина X имеет распределение Пуассона с параметром , если ее функция массы вероятности задается следующим образом: [2] : 60


где
- k — количество появлений ( )
- e — число Эйлера ( )
- k ! = k ( k– 1) ··· (3)(2)(1) — факториал .


Положительное действительное число λ равно ожидаемому значению X , а также его дисперсии . [13]

Распределение Пуассона может быть применено к системам с большим числом возможных событий, каждое из которых является редким . Число таких событий, которые происходят в течение фиксированного интервала времени, при правильных обстоятельствах является случайным числом с распределением Пуассона.
Уравнение можно адаптировать, если вместо среднего числа событий нам дана средняя скорость , с которой происходят события. Тогда и: [14]




Примеры

Распределение Пуассона может быть полезно для моделирования таких событий, как:
- количество метеоритов диаметром более 1 метра, падающих на Землю за год;
- количество лазерных фотонов, попадающих на детектор за определенный промежуток времени;
- количество студентов, получивших низкую и высокую оценку на экзамене; и
- места дефектов и дислокаций в материалах.
Примерами появления случайных точек в пространстве являются: места падения астероидов на Землю (двумерные), места дефектов в материале (трехмерные) и места расположения деревьев в лесу (двумерные). [15]
Предположения и обоснованность
Распределение Пуассона является подходящей моделью, если верны следующие предположения:
- k — неотрицательное целое число, представляющее собой количество раз, когда событие происходит в течение интервала.
- Наступление одного события не влияет на вероятность наступления второго события.
- Средняя скорость, с которой происходят события, не зависит от каких-либо происшествий.
- Два события не могут произойти в один и тот же момент.
Если эти условия верны, то k является пуассоновской случайной величиной; распределение k является распределением Пуассона.
Распределение Пуассона также является пределом биномиального распределения , для которого вероятность успеха для каждой попытки равна λ, деленной на число попыток, поскольку число попыток стремится к бесконечности (см. Связанные распределения).
Примеры вероятностей для распределений Пуассона
На конкретной реке паводки происходят в среднем раз в 100 лет. Рассчитайте вероятность k = 0, 1, 2, 3, 4, 5 или 6 паводков за 100-летний интервал, предполагая, что модель Пуассона подходит. Поскольку средняя частота событий составляет одно наводнение за 100 лет, λ = 1 |
Вероятность от 0 до 6 паводков за 100-летний период. |




Сообщается, что среднее количество голов в матче чемпионата мира по футболу составляет приблизительно 2,5, и модель Пуассона здесь уместна. [16] Поскольку средняя частота событий составляет 2,5 гола за матч, λ = 2,5. |
Вероятность от 0 до 7 голов в матче. |




Однажды в интервале событий: Частный случайλ= 1 ик= 0
Предположим, что астрономы подсчитали, что крупные метеориты (больше определенного размера) падают на Землю в среднем раз в 100 лет ( λ = 1 событие за 100 лет), и что количество падений метеоритов следует распределению Пуассона. Какова вероятность k = 0 падений метеоритов в течение следующих 100 лет?

При этих предположениях вероятность того, что в течение следующих 100 лет на Землю не упадет ни одного крупного метеорита, составляет примерно 0,37. Оставшиеся 1 − 0,37 = 0,63 представляют собой вероятность падения 1, 2, 3 или более крупных метеоритов в течение следующих 100 лет. В приведенном выше примере наводнение из-за разлива происходило раз в 100 лет ( λ = 1). Вероятность отсутствия наводнений из-за разлива в течение 100 лет составила примерно 0,37 по тем же расчетам.
В общем, если событие происходит в среднем один раз за интервал ( λ = 1), и события следуют распределению Пуассона, то P (0 событий в следующем интервале) = 0,37. Кроме того, P (ровно одно событие в следующем интервале) = 0,37, как показано в таблице для паводков.
Примеры, нарушающие предположения Пуассона
Число студентов, прибывающих в студенческий союз в минуту, скорее всего, не будет подчиняться распределению Пуассона, поскольку скорость не является постоянной (низкая скорость во время занятий, высокая скорость между занятиями), а прибытие отдельных студентов не является независимым (студенты, как правило, приходят группами). Непостоянная скорость прибытия может быть смоделирована как смешанное распределение Пуассона , а прибытие групп, а не отдельных студентов, как сложный процесс Пуассона .
Число землетрясений магнитудой 5 в год в стране может не подчиняться распределению Пуассона, если одно крупное землетрясение увеличивает вероятность повторных толчков аналогичной магнитуды.
Примеры, в которых гарантировано хотя бы одно событие, не распределены по закону Пуассона, но могут быть смоделированы с использованием усеченного до нуля распределения Пуассона .
Распределения количества, в которых число интервалов с нулевыми событиями выше, чем предсказывает модель Пуассона, можно смоделировать с помощью модели с завышением нуля .
Характеристики
Описательная статистика
- Ожидаемое значение случайной величины Пуассона равно λ .
- Дисперсия случайной величины Пуассона также равна λ .
- Коэффициент вариации равен , а индекс дисперсии равен 1. [8] : 163
- Среднее абсолютное отклонение от среднего составляет [8] : 163
- Мода случайной величины , распределенной по Пуассону, с нецелым λ равна наибольшему целому числу, меньшему или равному λ . Это также записывается как floor ( λ ). Когда λ — положительное целое число, моды равны λ и λ − 1.
- Все кумулянты распределения Пуассона равны ожидаемому значению λ . Факториальный момент n распределения Пуассона равен λ n .
- Ожидаемое значение процесса Пуассона иногда разлагается на произведение интенсивности и экспозиции (или, в более общем смысле, выражается как интеграл «функции интенсивности» по времени или пространству, иногда описываемый как «экспозиция»). [17]

![{\displaystyle \operatorname {E} [\ |X-\lambda |\ ]={\frac {2\lambda ^{\lfloor \lambda \rfloor +1}e^{-\lambda }}{\lfloor \lambda \rfloor !}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f38314ac3cdef3237f4321117fbf030a1115f6b9)

Медиана
Границы для медианы ( ) распределения известны и являются точными : [18]


Высшие моменты
Высшие нецентрированные моменты m k распределения Пуассона являются полиномами Тушара по λ : где фигурные скобки { } обозначают числа Стирлинга второго рода . [19] [1] : 6 Другими словами, когда ожидаемое значение установлено равным λ = 1, формула Добински подразумевает, что n -й момент равен числу разбиений множества размера n .

![{\displaystyle E[X]=\lambda ,\quad E[X(X-1)]=\lambda ^{2},\quad E[X(X-1)(X-2)]=\lambda ^{3},\cdots }](https://wikimedia.org/api/rest_v1/media/math/render/svg/f27f18d1393a99b37c525e21e568f340cf27889d)
Простая верхняя граница: [20]
![{\displaystyle m_{k}=E[X^{k}]\leq \left({\frac {k}{\log(k/\lambda +1)}}\right)^{k}\leq \lambda ^{k}\exp \left({\frac {k^{2}}{2\lambda }}\right).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18d2997208e48609996f73dc03db70e997b01b29)
Суммы случайных величин, распределенных по закону Пуассона
Если для независимы , то [21] : 65 Обратной теоремой является теорема Райкова , которая гласит, что если сумма двух независимых случайных величин распределена по закону Пуассона, то таковыми являются и каждая из этих двух независимых случайных величин. [22] [23]



Максимальная энтропия
Это распределение с максимальной энтропией среди множества обобщенных биномиальных распределений со средним значением и , [24] где обобщенное биномиальное распределение определяется как распределение суммы N независимых, но не одинаково распределенных переменных Бернулли.


Другие свойства
- Распределения Пуассона являются бесконечно делимыми распределениями вероятностей. [25] : 233 [8] : 164
- Направленное расхождение Кульбака–Лейблера от определяется выражением
- Если — целое число, то удовлетворяет и [26] [ проверка не пройдена — см. обсуждение ]
- Границы для хвостовых вероятностей случайной величины Пуассона можно вывести с использованием аргумента границы Чернова . [27] : 97-98
- Вероятность верхнего хвоста может быть сужена (по крайней мере, в два раза) следующим образом: [28]





![{\displaystyle \Pr(Y\geq E[Y])\geq {\frac {1}{2}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c5b13690a640b1826b92b683358e58098f957138)
![{\displaystyle \Pr(Y\leq E[Y])\geq {\frac {1}{2}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/14e3c38659a011ac0e4b6dd42cc920e61e92b936)



где — расхождение Кульбака–Лейблера от .



- Неравенства, связывающие функцию распределения случайной величины Пуассона со стандартной нормальной функцией распределения , следующие: [29] где — расхождение Кульбака–Лейблера от , а — расхождение Кульбака–Лейблера от .







Пуассоновские гонки
Пусть и — независимые случайные величины, тогда имеем, что



Верхняя граница доказана с использованием стандартной границы Чернова.
Нижнюю границу можно доказать, заметив, что есть вероятность того, что где , которая ограничена снизу где есть относительная энтропия (см. статью о границах хвостов биномиальных распределений для получения подробной информации). Далее отметив, что и вычислив нижнюю границу безусловной вероятности, получаем результат. Более подробную информацию можно найти в приложении к Kamath et al. [30]






Связанные дистрибутивы
Как биномиальное распределение с бесконечно малыми временными шагами
Распределение Пуассона может быть получено как предельный случай биномиального распределения , когда число попыток стремится к бесконечности, а ожидаемое число успехов остается фиксированным — см. закон редких событий ниже. Следовательно, его можно использовать в качестве приближения биномиального распределения, если n достаточно велико, а p достаточно мало. Распределение Пуассона является хорошим приближением биномиального распределения, если n не менее 20, а p меньше или равно 0,05, и превосходным приближением, если n ≥ 100 и np ≤ 10. [31] Позволяя и быть соответствующими функциями кумулятивной плотности биномиального и пуассоновского распределений, имеем: Один вывод этого использует функции генерации вероятности . [32] Рассмотрим испытание Бернулли (подбрасывание монеты), вероятность одного успеха (или ожидаемое число успехов) которого находится в пределах заданного интервала. Разбейте интервал на n частей и выполните испытание в каждом подынтервале с вероятностью . Вероятность k успехов из n попыток на всем интервале затем определяется биномиальным распределением






производящая функция которой:

Принимая предел при увеличении n до бесконечности (при фиксированном x ) и применяя определение предела произведения экспоненциальной функции , это сводится к производящей функции распределения Пуассона:

Общий
- Если и независимы, то разность следует распределению Скеллама .
- Если и независимы, то распределение условного значения является биномиальным .В частности, если тогда В более общем случае, если X 1 , X 2 , ..., X n являются независимыми случайными величинами Пуассона с параметрами λ 1 , λ 2 , ..., λ n , то
- учитывая , что следует, что на самом деле,
- Если и распределение условного на X = k является биномиальным распределением , то распределение Y следует распределению Пуассона. Фактически, если условное на следует полиномиальному распределению , то каждое следует независимому распределению Пуассона.
- Распределение Пуассона является частным случаем дискретного составного распределения Пуассона (или прерывистого распределения Пуассона) только с одним параметром. [33] [34] Дискретное составное распределение Пуассона может быть выведено из предельного распределения одномерного полиномиального распределения. Это также частный случай составного распределения Пуассона .
- Для достаточно больших значений λ (скажем, λ >1000) нормальное распределение со средним λ и дисперсией λ (стандартное отклонение ) является отличным приближением к распределению Пуассона. Если λ больше примерно 10, то нормальное распределение является хорошим приближением, если выполняется соответствующая коррекция непрерывности , т. е. если P( X ≤ x ) , где x — неотрицательное целое число, заменяется на P( X ≤ x + 0,5) .
- Преобразование, стабилизирующее дисперсию : Если то [8] : 168 и [35] : 196 При этом преобразовании сходимость к нормальности (при увеличении) происходит гораздо быстрее, чем для непреобразованной переменной. [ необходима ссылка ] Доступны и другие, немного более сложные преобразования, стабилизирующие дисперсию, [8] : 168 одним из которых является преобразование Анскомба . [36] См. Преобразование данных (статистика) для более общего использования преобразований.
- Если для каждого t > 0 число прибытий в интервале времени [0, t ] следует распределению Пуассона со средним значением λt , то последовательность времен между прибытиями является независимыми и одинаково распределенными экспоненциальными случайными величинами со средним значением 1/ λ . [37] : 317–319
- Кумулятивные функции распределения Пуассона и хи-квадрат связаны следующим образом: [8] : 167 и [8] : 158


























приближение Пуассона
Предположим , что где тогда [38] распределено мультиномиально при условии





Это означает [27] : 101-102 , среди прочего, что для любой неотрицательной функции, если она распределена мультиномиально, то где


![{\displaystyle \operatorname {E} [f(Y_{1},Y_{2},\dots ,Y_{n})]\leq e{\sqrt {m}}\operatorname {E} [f(X_{1},X_{2},\dots ,X_{n})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d196f4817af3673334cad96f9aa090d2ae3cb7e)

Множитель можно заменить на 2, если дополнительно предположить, что он монотонно возрастает или убывает.


Двумерное распределение Пуассона
Это распределение было распространено на двумерный случай. [39] Производящая функция для этого распределения имеет вид
![{\displaystyle g(u,v)=\exp[(\theta _{1}-\theta _{12})(u-1)+(\theta _{2}-\theta _{12})(v-1)+\theta _{12}(uv-1)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0d994b2c4f3b36c80cfd0b97ed72fe289c0855d4)
с

Предельные распределения — это распределения Пуассона ( θ 1 ) и Пуассона ( θ 2 ), а коэффициент корреляции ограничен диапазоном

Простой способ создания двумерного распределения Пуассона — взять три независимых распределения Пуассона со средними значениями , а затем задать Вероятностную функцию двумерного распределения Пуассона:





Свободное распределение Пуассона
Свободное распределение Пуассона [40] с размером и скоростью скачка возникает в свободной теории вероятностей как предел повторной свободной свертки при N → ∞ .


Другими словами, пусть будут случайными величинами, так что имеет значение с вероятностью и значение 0 с оставшейся вероятностью. Предположим также, что семейство свободно независимо . Тогда предел по закону задается свободным законом Пуассона с параметрами






Это определение аналогично одному из способов, с помощью которого классическое распределение Пуассона получается из (классического) процесса Пуассона.
Мера, связанная со свободным законом Пуассона, определяется выражением [41] , где и имеет поддержку


![{\displaystyle [\alpha (1-{\sqrt {\lambda }})^{2},\alpha (1+{\sqrt {\lambda }})^{2}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e632a5959c5dd7a328d80a02e2d9134178a173e1)
Этот закон также возникает в теории случайных матриц как закон Марченко–Пастура . Его свободные кумулянты равны

Некоторые преобразования этого закона
Мы приводим значения некоторых важных преобразований свободного закона Пуассона; вычисление можно найти, например, в книге « Лекции по комбинаторике свободной вероятности» А. Ники и Р. Шпайхера [42].
R-преобразование свободного закона Пуассона определяется выражением

Преобразование Коши (которое является отрицательным преобразованием Стилтьеса ) определяется выражением

S-преобразование задается в случае, если


Вейбулл и стабильный счет
Функция массы вероятности Пуассона может быть выражена в форме, аналогичной распределению произведения распределения Вейбулла и варианту формы устойчивого распределения счета . Переменная может рассматриваться как обратная параметру устойчивости Леви в устойчивом распределении счета: где — стандартное устойчивое распределение счета формы , а — стандартное распределение Вейбулла формы


![{\displaystyle f(k;\lambda )=\int _{0}^{\infty }{\frac {1}{u}}\,W_{k+1}\left({\frac {\lambda }{u}}\right)\left[(k+1)u^{k}\,{\mathfrak {N}}_{\frac {1}{k+1}}(u^{k+1})\right]\,du,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2646e3d03684519bf4726333b17d41b116396efa)




Статистический вывод
Оценка параметров
Учитывая выборку из n измеренных значений для i = 1, ..., n , мы хотим оценить значение параметра λ пуассоновской популяции, из которой была взята выборка. Оценка максимального правдоподобия равна [43]


Поскольку каждое наблюдение имеет ожидание λ, то же самое относится и к выборочному среднему. Следовательно, оценка максимального правдоподобия является несмещенной оценкой λ . Она также является эффективной оценкой, поскольку ее дисперсия достигает нижней границы Крамера–Рао (CRLB). [44] Следовательно, она является несмещенной с минимальной дисперсией . Также можно доказать, что сумма (и, следовательно, выборочное среднее, поскольку оно является функцией суммы один к одному) является полной и достаточной статистикой для λ .
Для доказательства достаточности можно использовать теорему о факторизации . Рассмотрим разбиение функции массы вероятности совместного распределения Пуассона для выборки на две части: одну, которая зависит исключительно от выборки , называемую , и другую, которая зависит от параметра и выборки только через функцию Тогда является достаточной статистикой для






Первый член зависит только от . Второй член зависит от выборки только через Таким образом, достаточно.


Чтобы найти параметр λ , который максимизирует функцию вероятности для популяции Пуассона, мы можем использовать логарифм функции правдоподобия:

Берем производную по λ и сравниваем ее с нулем:


Решение относительно λ дает стационарную точку.

Итак, λ — это среднее значение k i . Получение знака второй производной L в стационарной точке определит, каким экстремальным значением является λ .

Оценка второй производной в стационарной точке дает:

что является отрицательным значением n , умноженным на обратную величину среднего значения k i . Это выражение отрицательно, когда среднее значение положительно. Если это выполняется, то стационарная точка максимизирует функцию вероятности.
Для полноты семейство распределений называется полным тогда и только тогда, когда подразумевается, что для всех Если индивидуумы являются независимыми , то Зная распределение, которое мы хотим исследовать, легко видеть, что статистика является полной.






Для того чтобы это равенство выполнялось, должно быть равно 0. Это следует из того факта, что ни один из других членов не будет равен 0 для всех в сумме и для всех возможных значений Следовательно, для всех следует, что и было показано, что статистика является полной.



Доверительный интервал
Доверительный интервал для среднего значения распределения Пуассона может быть выражен с использованием соотношения между кумулятивными функциями распределения Пуассона и распределения хи-квадрат . Распределение хи-квадрат само по себе тесно связано с гамма-распределением , и это приводит к альтернативному выражению. При наличии наблюдения k из распределения Пуассона со средним значением μ доверительный интервал для μ с уровнем достоверности 1 – α равен

или эквивалентно,

где — квантильная функция (соответствующая нижней хвостовой области p ) распределения хи-квадрат с n степенями свободы, а — квантильная функция гамма -распределения с параметром формы n и параметром масштаба 1. [8] : 176-178 [45] Этот интервал является « точным » в том смысле, что его вероятность покрытия никогда не бывает меньше номинала 1 – α .


Когда квантили гамма-распределения недоступны, была предложена точная аппроксимация этого точного интервала (основанная на преобразовании Уилсона-Хилферти ): [46]

где обозначает стандартное нормальное отклонение с верхней зоной хвоста α / 2 .

Для применения этих формул в том же контексте, что и выше (при наличии выборки из n измеренных значений k i , каждое из которых взято из распределения Пуассона со средним λ ), можно установить

calculate an interval for μ = n λ , and then derive the interval for λ.
Bayesian inference
In Bayesian inference, the conjugate prior for the rate parameter λ of the Poisson distribution is the gamma distribution.[47] Let

denote that λ is distributed according to the gamma density g parameterized in terms of a shape parameter α and an inverse scale parameter β:

Then, given the same sample of n measured values ki as before, and a prior of Gamma(α, β), the posterior distribution is

Note that the posterior mean is linear and is given by
![{\displaystyle E[\lambda \mid k_{1},\ldots ,k_{n}]={\frac {\alpha +\sum _{i=1}^{n}k_{i}}{\beta +n}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/00dc8f117cfc4b31656f10b620be9392cfe96f47)
It can be shown that gamma distribution is the only prior that induces linearity of the conditional mean. Moreover, a converse result exists which states that if the conditional mean is close to a linear function in the distance than the prior distribution of λ must be close to gamma distribution in Levy distance.[48]

The posterior mean E[λ] approaches the maximum likelihood estimate in the limit as which follows immediately from the general expression of the mean of the gamma distribution.


The posterior predictive distribution for a single additional observation is a negative binomial distribution,[49]: 53 sometimes called a gamma–Poisson distribution.
Simultaneous estimation of multiple Poisson means
Suppose is a set of independent random variables from a set of Poisson distributions, each with a parameter and we would like to estimate these parameters. Then, Clevenson and Zidek show that under the normalized squared error loss when then, similar as in Stein's example for the Normal means, the MLE estimator is inadmissible. [50]







In this case, a family of minimax estimators is given for any and as[51]



Occurrence and applications
This article needs additional citations for verification. (December 2019) |

Some applications of the Poisson distribution to count data (number of events):[52]
- telecommunication: telephone calls arriving in a system,
- astronomy: photons arriving at a telescope,
- chemistry: the molar mass distribution of a living polymerization,[53]
- biology: the number of mutations on a strand of DNA per unit length,
- management: customers arriving at a counter or call centre,
- finance and insurance: number of losses or claims occurring in a given period of time,
- seismology: asymptotic Poisson model of risk for large earthquakes,[54]
- radioactivity: decays in a given time interval in a radioactive sample,
- optics: number of photons emitted in a single laser pulse (a major vulnerability of quantum key distribution protocols, known as photon number splitting).
More examples of counting events that may be modelled as Poisson processes include:
- soldiers killed by horse-kicks each year in each corps in the Prussian cavalry. This example was used in a book by Ladislaus Bortkiewicz (1868–1931),[12]: 23-25
- yeast cells used when brewing Guinness beer. This example was used by William Sealy Gosset (1876–1937),[55][56]
- phone calls arriving at a call centre within a minute. This example was described by A.K. Erlang (1878–1929),[57]
- goals in sports involving two competing teams,[58]
- deaths per year in a given age group,
- jumps in a stock price in a given time interval,
- times a web server is accessed per minute (under an assumption of homogeneity),
- mutations in a given stretch of DNA after a certain amount of radiation,
- cells infected at a given multiplicity of infection,
- bacteria in a certain amount of liquid,[59]
- photons arriving on a pixel circuit at a given illumination over a given time period,
- landing of V-1 flying bombs on London during World War II, investigated by R. D. Clarke in 1946.[60]
In probabilistic number theory, Gallagher showed in 1976 that, if a certain version of the unproved prime r-tuple conjecture holds,[61] then the counts of prime numbers in short intervals would obey a Poisson distribution.[62]
Law of rare events

The rate of an event is related to the probability of an event occurring in some small subinterval (of time, space or otherwise). In the case of the Poisson distribution, one assumes that there exists a small enough subinterval for which the probability of an event occurring twice is "negligible". With this assumption one can derive the Poisson distribution from the binomial one, given only the information of expected number of total events in the whole interval.
Let the total number of events in the whole interval be denoted by Divide the whole interval into subintervals of equal size, such that (since we are interested in only very small portions of the interval this assumption is meaningful). This means that the expected number of events in each of the n subintervals is equal to




Now we assume that the occurrence of an event in the whole interval can be seen as a sequence of n Bernoulli trials, where the -th Bernoulli trial corresponds to looking whether an event happens at the subinterval with probability The expected number of total events in such trials would be the expected number of total events in the whole interval. Hence for each subdivision of the interval we have approximated the occurrence of the event as a Bernoulli process of the form As we have noted before we want to consider only very small subintervals. Therefore, we take the limit as goes to infinity.



In this case the binomial distribution converges to what is known as the Poisson distribution by the Poisson limit theorem.
In several of the above examples — such as, the number of mutations in a given sequence of DNA—the events being counted are actually the outcomes of discrete trials, and would more precisely be modelled using the binomial distribution, that is

In such cases n is very large and p is very small (and so the expectation n p is of intermediate magnitude). Then the distribution may be approximated by the less cumbersome Poisson distribution

This approximation is sometimes known as the law of rare events,[63]: 5 since each of the n individual Bernoulli events rarely occurs.
The name "law of rare events" may be misleading because the total count of success events in a Poisson process need not be rare if the parameter n p is not small. For example, the number of telephone calls to a busy switchboard in one hour follows a Poisson distribution with the events appearing frequent to the operator, but they are rare from the point of view of the average member of the population who is very unlikely to make a call to that switchboard in that hour.
The variance of the binomial distribution is 1 − p times that of the Poisson distribution, so almost equal when p is very small.
The word law is sometimes used as a synonym of probability distribution, and convergence in law means convergence in distribution. Accordingly, the Poisson distribution is sometimes called the "law of small numbers" because it is the probability distribution of the number of occurrences of an event that happens rarely but has very many opportunities to happen. The Law of Small Numbers is a book by Ladislaus Bortkiewicz about the Poisson distribution, published in 1898.[12][64]
Poisson point process
The Poisson distribution arises as the number of points of a Poisson point process located in some finite region. More specifically, if D is some region space, for example Euclidean space Rd, for which |D|, the area, volume or, more generally, the Lebesgue measure of the region is finite, and if N(D) denotes the number of points in D, then

Poisson regression and negative binomial regression
Poisson regression and negative binomial regression are useful for analyses where the dependent (response) variable is the count (0, 1, 2, ... ) of the number of events or occurrences in an interval.
Biology
The Luria–Delbrück experiment tested against the hypothesis of Lamarckian evolution, which should result in a Poisson distribution.
Katz and Miledi measured the membrane potential with and without the presence of acetylcholine (ACh).[65] When ACh is present, ion channels on the membrane would be open randomly at a small fraction of the time. As there are a large number of ion channels each open for a small fraction of the time, the total number of ion channels open at any moment is Poisson distributed. When ACh is not present, effectively no ion channels are open. The membrane potential is . Subtracting the effect of noise, Katz and Miledi found the mean and variance of membrane potential to be , giving . (pp. 94-95 [66])



During each cellular replication event, the number of mutations is roughly Poisson distributed.[67] For example, the HIV virus has 10,000 base pairs, and has a mutation rate of about 1 per 30,000 base pairs, meaning the number of mutations per replication event is distributed as . (p. 64 [66])

Other applications in science
In a Poisson process, the number of observed occurrences fluctuates about its mean λ with a standard deviation These fluctuations are denoted as Poisson noise or (particularly in electronics) as shot noise.

The correlation of the mean and standard deviation in counting independent discrete occurrences is useful scientifically. By monitoring how the fluctuations vary with the mean signal, one can estimate the contribution of a single occurrence, even if that contribution is too small to be detected directly. For example, the charge e on an electron can be estimated by correlating the magnitude of an electric current with its shot noise. If N electrons pass a point in a given time t on the average, the mean current is ; since the current fluctuations should be of the order (i.e., the standard deviation of the Poisson process), the charge can be estimated from the ratio [citation needed]




An everyday example is the graininess that appears as photographs are enlarged; the graininess is due to Poisson fluctuations in the number of reduced silver grains, not to the individual grains themselves. By correlating the graininess with the degree of enlargement, one can estimate the contribution of an individual grain (which is otherwise too small to be seen unaided).[citation needed]
In causal set theory the discrete elements of spacetime follow a Poisson distribution in the volume.
The Poisson distribution also appears in quantum mechanics, especially quantum optics. Namely, for a quantum harmonic oscillator system in a coherent state, the probability of measuring a particular energy level has a Poisson distribution.
Computational methods
The Poisson distribution poses two different tasks for dedicated software libraries: evaluating the distribution , and drawing random numbers according to that distribution.

Evaluating the Poisson distribution
Computing for given and is a trivial task that can be accomplished by using the standard definition of in terms of exponential, power, and factorial functions. However, the conventional definition of the Poisson distribution contains two terms that can easily overflow on computers: λk and k!. The fraction of λk to k! can also produce a rounding error that is very large compared to e−λ, and therefore give an erroneous result. For numerical stability the Poisson probability mass function should therefore be evaluated as

![{\displaystyle \!f(k;\lambda )=\exp \left[k\ln \lambda -\lambda -\ln \Gamma (k+1)\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/83a8a374612dfba5c3e699450970a5b2330925c3)
which is mathematically equivalent but numerically stable. The natural logarithm of the Gamma function can be obtained using the lgamma function in the C standard library (C99 version) or R, the gammaln function in MATLAB or SciPy, or the log_gamma function in Fortran 2008 and later.
Some computing languages provide built-in functions to evaluate the Poisson distribution, namely
- R: function
dpois(x, lambda); - Excel: function
POISSON( x, mean, cumulative), with a flag to specify the cumulative distribution; - Mathematica: univariate Poisson distribution as
PoissonDistribution[],[68] bivariate Poisson distribution asMultivariatePoissonDistribution[{ }],.[69]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Random variate generation
The less trivial task is to draw integer random variate from the Poisson distribution with given
Solutions are provided by:
- R: function
rpois(n, lambda); - GNU Scientific Library (GSL): function gsl_ran_poisson
A simple algorithm to generate random Poisson-distributed numbers (pseudo-random number sampling) has been given by Knuth:[70]: 137-138
algorithm poisson random number (Knuth): init: Let L ← e−λ, k ← 0 and p ← 1. do: k ← k + 1. Generate uniform random number u in [0,1] and let p ← p × u. while p > L. return k − 1.
The complexity is linear in the returned value k, which is λ on average. There are many other algorithms to improve this. Some are given in Ahrens & Dieter, see § References below.
For large values of λ, the value of L = e−λ may be so small that it is hard to represent. This can be solved by a change to the algorithm which uses an additional parameter STEP such that e−STEP does not underflow: [citation needed]
algorithm poisson random number (Junhao, based on Knuth): init: Let λLeft ← λ, k ← 0 and p ← 1. do: k ← k + 1. Generate uniform random number u in (0,1) and let p ← p × u. while p < 1 and λLeft > 0: if λLeft > STEP: p ← p × eSTEP λLeft ← λLeft − STEP else: p ← p × eλLeft λLeft ← 0 while p > 1. return k − 1.
The choice of STEP depends on the threshold of overflow. For double precision floating point format the threshold is near e700, so 500 should be a safe STEP.
Other solutions for large values of λ include rejection sampling and using Gaussian approximation.
Inverse transform sampling is simple and efficient for small values of λ, and requires only one uniform random number u per sample. Cumulative probabilities are examined in turn until one exceeds u.
algorithm Poisson generator based upon the inversion by sequential search:[71]: 505 init: Let x ← 0, p ← e−λ, s ← p. Generate uniform random number u in [0,1]. while u > s do: x ← x + 1. p ← p × λ / x. s ← s + p. return x.
See also
- Binomial distribution
- Compound Poisson distribution
- Conway–Maxwell–Poisson distribution
- Erlang distribution
- Exponential distribution
- Gamma distribution
- Hermite distribution
- Index of dispersion
- Negative binomial distribution
- Poisson clumping
- Poisson point process
- Poisson regression
- Poisson sampling
- Poisson wavelet
- Queueing theory
- Renewal theory
- Robbins lemma
- Skellam distribution
- Tweedie distribution
- Zero-inflated model
- Zero-truncated Poisson distribution
References
Citations
- ^ a b Haight, Frank A. (1967). Handbook of the Poisson Distribution. New York, NY, US: John Wiley & Sons. ISBN 978-0-471-33932-8.
- ^ a b Yates, Roy D.; Goodman, David J. (2014). Probability and Stochastic Processes: A Friendly Introduction for Electrical and Computer Engineers (2nd ed.). Hoboken, NJ: Wiley. ISBN 978-0-471-45259-1.
- ^ Ross, Sheldon M. (2014). Introduction to Probability Models (11th ed.). Academic Press.
- ^ Poisson, Siméon D. (1837). Probabilité des jugements en matière criminelle et en matière civile, précédées des règles générales du calcul des probabilités [Research on the Probability of Judgments in Criminal and Civil Matters] (in French). Paris, France: Bachelier.
- ^ de Moivre, Abraham (1711). "De mensura sortis, seu, de probabilitate eventuum in ludis a casu fortuito pendentibus" [On the Measurement of Chance, or, on the Probability of Events in Games Depending Upon Fortuitous Chance]. Philosophical Transactions of the Royal Society (in Latin). 27 (329): 213–264. doi:10.1098/rstl.1710.0018.
- ^ de Moivre, Abraham (1718). The Doctrine of Chances: Or, A Method of Calculating the Probability of Events in Play. London, Great Britain: W. Pearson. ISBN 9780598843753.
- ^ de Moivre, Abraham (1721). "Of the Laws of Chance". In Motte, Benjamin (ed.). The Philosophical Transactions from the Year MDCC (where Mr. Lowthorp Ends) to the Year MDCCXX. Abridg'd, and Dispos'd Under General Heads (in Latin). Vol. I. London, Great Britain: R. Wilkin, R. Robinson, S. Ballard, W. and J. Innys, and J. Osborn. pp. 190–219.
- ^ a b c d e f g h i Johnson, Norman L.; Kemp, Adrienne W.; Kotz, Samuel (2005). "Poisson Distribution". Univariate Discrete Distributions (3rd ed.). New York, NY, US: John Wiley & Sons, Inc. pp. 156–207. doi:10.1002/0471715816. ISBN 978-0-471-27246-5.
- ^ Stigler, Stephen M. (1982). "Poisson on the Poisson Distribution". Statistics & Probability Letters. 1 (1): 33–35. doi:10.1016/0167-7152(82)90010-4.
- ^ Hald, Anders; de Moivre, Abraham; McClintock, Bruce (1984). "A. de Moivre: 'De Mensura Sortis' or 'On the Measurement of Chance'". International Statistical Review / Revue Internationale de Statistique. 52 (3): 229–262. doi:10.2307/1403045. JSTOR 1403045.
- ^ Newcomb, Simon (1860). "Notes on the theory of probabilities". The Mathematical Monthly. 2 (4): 134–140.
- ^ a b c von Bortkiewitsch, Ladislaus (1898). Das Gesetz der kleinen Zahlen [The law of small numbers] (in German). Leipzig, Germany: B.G. Teubner. pp. 1, 23–25.
- On page 1, Bortkiewicz presents the Poisson distribution.
- On pages 23–25, Bortkiewitsch presents his analysis of "4. Beispiel: Die durch Schlag eines Pferdes im preußischen Heere Getöteten." [4. Example: Those killed in the Prussian army by a horse's kick.]
- ^ For the proof, see: Proof wiki: expectation and Proof wiki: variance
- ^ Kardar, Mehran (2007). Statistical Physics of Particles. Cambridge University Press. p. 42. ISBN 978-0-521-87342-0. OCLC 860391091.
- ^ Dekking, Frederik Michel; Kraaikamp, Cornelis; Lopuhaä, Hendrik Paul; Meester, Ludolf Erwin (2005). A Modern Introduction to Probability and Statistics. Springer Texts in Statistics. p. 167. doi:10.1007/1-84628-168-7. ISBN 978-1-85233-896-1.
- ^ Ugarte, M.D.; Militino, A.F.; Arnholt, A.T. (2016). Probability and Statistics with R (2nd ed.). Boca Raton, FL, US: CRC Press. ISBN 978-1-4665-0439-4.
- ^ Helske, Jouni (2017). "KFAS: Exponential Family State Space Models in R". Journal of Statistical Software. 78 (10). arXiv:1612.01907. doi:10.18637/jss.v078.i10. S2CID 14379617.
- ^ Choi, Kwok P. (1994). "On the medians of gamma distributions and an equation of Ramanujan". Proceedings of the American Mathematical Society. 121 (1): 245–251. doi:10.2307/2160389. JSTOR 2160389.
- ^ Riordan, John (1937). "Moment Recurrence Relations for Binomial, Poisson and Hypergeometric Frequency Distributions" (PDF). Annals of Mathematical Statistics. 8 (2): 103–111. doi:10.1214/aoms/1177732430. JSTOR 2957598.
- ^ D. Ahle, Thomas (2022). "Sharp and simple bounds for the raw moments of the Binomial and Poisson distributions". Statistics & Probability Letters. 182: 109306. arXiv:2103.17027. doi:10.1016/j.spl.2021.109306.
- ^ Lehmann, Erich Leo (1986). Testing Statistical Hypotheses (2nd ed.). New York, NJ, US: Springer Verlag. ISBN 978-0-387-94919-2.
- ^ Raikov, Dmitry (1937). "On the decomposition of Poisson laws". Comptes Rendus de l'Académie des Sciences de l'URSS. 14: 9–11.
- ^ von Mises, Richard (1964). Mathematical Theory of Probability and Statistics. New York, NJ, US: Academic Press. doi:10.1016/C2013-0-12460-9. ISBN 978-1-4832-3213-3.
- ^ Harremoes, P. (July 2001). "Binomial and Poisson distributions as maximum entropy distributions". IEEE Transactions on Information Theory. 47 (5): 2039–2041. doi:10.1109/18.930936. S2CID 16171405.
- ^ Laha, Radha G.; Rohatgi, Vijay K. (1979). Probability Theory. New York, NJ, US: John Wiley & Sons. ISBN 978-0-471-03262-5.
- ^ Mitzenmacher, Michael (2017). Probability and computing: Randomization and probabilistic techniques in algorithms and data analysis. Eli Upfal (2nd ed.). Cambridge, UK. Exercise 5.14. ISBN 978-1-107-15488-9. OCLC 960841613.
{{cite book}}: CS1 maint: location missing publisher (link) - ^ a b Mitzenmacher, Michael; Upfal, Eli (2005). Probability and Computing: Randomized Algorithms and Probabilistic Analysis. Cambridge, UK: Cambridge University Press. ISBN 978-0-521-83540-4.
- ^ Short, Michael (2013). "Improved Inequalities for the Poisson and Binomial Distribution and Upper Tail Quantile Functions". ISRN Probability and Statistics. 2013. Corollary 6. doi:10.1155/2013/412958.
- ^ Short, Michael (2013). "Improved Inequalities for the Poisson and Binomial Distribution and Upper Tail Quantile Functions". ISRN Probability and Statistics. 2013. Theorem 2. doi:10.1155/2013/412958.
- ^ Kamath, Govinda M.; Şaşoğlu, Eren; Tse, David (14–19 June 2015). Optimal haplotype assembly from high-throughput mate-pair reads. 2015 IEEE International Symposium on Information Theory (ISIT). Hong Kong, China. pp. 914–918. arXiv:1502.01975. doi:10.1109/ISIT.2015.7282588. S2CID 128634.
- ^ Prins, Jack (2012). "6.3.3.1. Counts Control Charts". e-Handbook of Statistical Methods. NIST/SEMATECH. Retrieved 20 September 2019.
- ^ Feller, William. An Introduction to Probability Theory and its Applications.
- ^ Zhang, Huiming; Liu, Yunxiao; Li, Bo (2014). "Notes on discrete compound Poisson model with applications to risk theory". Insurance: Mathematics and Economics. 59: 325–336. doi:10.1016/j.insmatheco.2014.09.012.
- ^ Zhang, Huiming; Li, Bo (2016). "Characterizations of discrete compound Poisson distributions". Communications in Statistics - Theory and Methods. 45 (22): 6789–6802. doi:10.1080/03610926.2014.901375. S2CID 125475756.
- ^ McCullagh, Peter; Nelder, John (1989). Generalized Linear Models. Monographs on Statistics and Applied Probability. Vol. 37. London, UK: Chapman and Hall. ISBN 978-0-412-31760-6.
- ^ Anscombe, Francis J. (1948). "The transformation of Poisson, binomial and negative binomial data". Biometrika. 35 (3–4): 246–254. doi:10.1093/biomet/35.3-4.246. JSTOR 2332343.
- ^ Ross, Sheldon M. (2010). Introduction to Probability Models (10th ed.). Boston, MA: Academic Press. ISBN 978-0-12-375686-2.
- ^ "1.7.7 – Relationship between the Multinomial and Poisson | STAT 504". Archived from the original on 6 August 2019. Retrieved 6 August 2019.
- ^ Loukas, Sotirios; Kemp, C. David (1986). "The Index of Dispersion Test for the Bivariate Poisson Distribution". Biometrics. 42 (4): 941–948. doi:10.2307/2530708. JSTOR 2530708.
- ^ Free Random Variables by D. Voiculescu, K. Dykema, A. Nica, CRM Monograph Series, American Mathematical Society, Providence RI, 1992
- ^ Alexandru Nica, Roland Speicher: Lectures on the Combinatorics of Free Probability. London Mathematical Society Lecture Note Series, Vol. 335, Cambridge University Press, 2006.
- ^ Lectures on the Combinatorics of Free Probability by A. Nica and R. Speicher, pp. 203–204, Cambridge Univ. Press 2006
- ^ Paszek, Ewa. "Maximum likelihood estimation – examples". cnx.org.
- ^ Van Trees, Harry L. (2013). Detection estimation and modulation theory. Kristine L. Bell, Zhi Tian (Second ed.). Hoboken, N.J. ISBN 978-1-299-66515-6. OCLC 851161356.
{{cite book}}: CS1 maint: location missing publisher (link) - ^ Garwood, Frank (1936). "Fiducial Limits for the Poisson Distribution". Biometrika. 28 (3/4): 437–442. doi:10.1093/biomet/28.3-4.437. JSTOR 2333958.
- ^ Breslow, Norman E.; Day, Nick E. (1987). Statistical Methods in Cancer Research. Vol. 2 — The Design and Analysis of Cohort Studies. Lyon, France: International Agency for Research on Cancer. ISBN 978-92-832-0182-3. Archived from the original on 8 August 2018. Retrieved 11 March 2012.
- ^ Fink, Daniel (1997). A Compendium of Conjugate Priors.
- ^ Dytso, Alex; Poor, H. Vincent (2020). "Estimation in Poisson noise: Properties of the conditional mean estimator". IEEE Transactions on Information Theory. 66 (7): 4304–4323. arXiv:1911.03744. doi:10.1109/TIT.2020.2979978. S2CID 207853178.
- ^ Gelman; Carlin, John B.; Stern, Hal S.; Rubin, Donald B. (2003). Bayesian Data Analysis (2nd ed.). Boca Raton, FL, US: Chapman & Hall/CRC. ISBN 1-58488-388-X.
- ^ Clevenson, M. Lawrence; Zidek, James V. (1975). "Simultaneous estimation of the means of independent Poisson laws". Journal of the American Statistical Association. 70 (351): 698–705. doi:10.1080/01621459.1975.10482497. JSTOR 2285958.
- ^ Berger, James O. (1985). Statistical Decision Theory and Bayesian Analysis. Springer Series in Statistics (2nd ed.). New York, NY: Springer-Verlag. Bibcode:1985sdtb.book.....B. doi:10.1007/978-1-4757-4286-2. ISBN 978-0-387-96098-2.
- ^ Rasch, Georg (1963). The Poisson Process as a Model for a Diversity of Behavioural Phenomena (PDF). 17th International Congress of Psychology. Vol. 2. Washington, DC: American Psychological Association. doi:10.1037/e685262012-108.
- ^ Flory, Paul J. (1940). "Molecular Size Distribution in Ethylene Oxide Polymers". Journal of the American Chemical Society. 62 (6): 1561–1565. Bibcode:1940JAChS..62.1561F. doi:10.1021/ja01863a066.
- ^ Lomnitz, Cinna (1994). Fundamentals of Earthquake Prediction. New York, NY: John Wiley & Sons. ISBN 0-471-57419-8. OCLC 647404423.
- ^ a student (1907). "On the error of counting with a haemacytometer". Biometrika. 5 (3): 351–360. doi:10.2307/2331633. JSTOR 2331633.
- ^ Boland, Philip J. (1984). "A biographical glimpse of William Sealy Gosset". The American Statistician. 38 (3): 179–183. doi:10.1080/00031305.1984.10483195. JSTOR 2683648.
- ^ Erlang, Agner K. (1909). "Sandsynlighedsregning og Telefonsamtaler" [Probability Calculation and Telephone Conversations]. Nyt Tidsskrift for Matematik (in Danish). 20 (B): 33–39. JSTOR 24528622.
- ^ Hornby, Dave (2014). "Football Prediction Model: Poisson Distribution". Sports Betting Online. Retrieved 19 September 2014.
- ^ Koyama, Kento; Hokunan, Hidekazu; Hasegawa, Mayumi; Kawamura, Shuso; Koseki, Shigenobu (2016). "Do bacterial cell numbers follow a theoretical Poisson distribution? Comparison of experimentally obtained numbers of single cells with random number generation via computer simulation". Food Microbiology. 60: 49–53. doi:10.1016/j.fm.2016.05.019. PMID 27554145.
- ^ Clarke, R. D. (1946). "An application of the Poisson distribution" (PDF). Journal of the Institute of Actuaries. 72 (3): 481. doi:10.1017/S0020268100035435.
- ^ Hardy, Godfrey H.; Littlewood, John E. (1923). "On some problems of "partitio numerorum" III: On the expression of a number as a sum of primes". Acta Mathematica. 44: 1–70. doi:10.1007/BF02403921.
- ^ Gallagher, Patrick X. (1976). "On the distribution of primes in short intervals". Mathematika. 23 (1): 4–9. doi:10.1112/s0025579300016442.
- ^ Cameron, A. Colin; Trivedi, Pravin K. (1998). Regression Analysis of Count Data. Cambridge, UK: Cambridge University Press. ISBN 978-0-521-63567-7.
- ^ Edgeworth, F.Y. (1913). "On the use of the theory of probabilities in statistics relating to society". Journal of the Royal Statistical Society. 76 (2): 165–193. doi:10.2307/2340091. JSTOR 2340091.
- ^ Katz, B.; Miledi, R. (August 1972). "The statistical nature of the acetylcholine potential and its molecular components". The Journal of Physiology. 224 (3): 665–699. doi:10.1113/jphysiol.1972.sp009918. ISSN 0022-3751. PMC 1331515. PMID 5071933.
- ^ a b Nelson, Philip Charles; Bromberg, Sarina; Hermundstad, Ann; Prentice, Jason (2015). Physical models of living systems. New York, NY: W.H. Freeman & Company, a Macmillan Education Imprint. ISBN 978-1-4641-4029-7. OCLC 891121698.
- ^ Foster, Patricia L. (1 January 2006), "Methods for Determining Spontaneous Mutation Rates", DNA Repair, Part B, Methods in Enzymology, vol. 409, Academic Press, pp. 195–213, doi:10.1016/S0076-6879(05)09012-9, ISBN 978-0-12-182814-1, PMC 2041832, PMID 16793403
- ^ "Wolfram Language: PoissonDistribution reference page". wolfram.com. Retrieved 8 April 2016.
- ^ "Wolfram Language: MultivariatePoissonDistribution reference page". wolfram.com. Retrieved 8 April 2016.
- ^ Knuth, Donald Ervin (1997). Seminumerical Algorithms. The Art of Computer Programming. Vol. 2 (3rd ed.). Addison Wesley. ISBN 978-0-201-89684-8.
- ^ Devroye, Luc (1986). "Discrete Univariate Distributions" (PDF). Non-Uniform Random Variate Generation. New York, NY: Springer-Verlag. pp. 485–553. doi:10.1007/978-1-4613-8643-8_10. ISBN 978-1-4613-8645-2.
Sources
- Ahrens, Joachim H.; Dieter, Ulrich (1974). "Computer Methods for Sampling from Gamma, Beta, Poisson and Binomial Distributions". Computing. 12 (3): 223–246. doi:10.1007/BF02293108. S2CID 37484126.
- Ahrens, Joachim H.; Dieter, Ulrich (1982). "Computer Generation of Poisson Deviates". ACM Transactions on Mathematical Software. 8 (2): 163–179. doi:10.1145/355993.355997. S2CID 12410131.
- Evans, Ronald J.; Boersma, J.; Blachman, N. M.; Jagers, A. A. (1988). "The Entropy of a Poisson Distribution: Problem 87-6". SIAM Review. 30 (2): 314–317. doi:10.1137/1030059.
