Нормализация базы данных
 | Эта статья требует внимания эксперта по базам данных . Подробности смотрите на странице обсуждения . ( Март 2018 ) |
Нормализация базы данных — это процесс структурирования реляционной базы данных в соответствии с серией так называемых нормальных форм с целью уменьшения избыточности данных и улучшения целостности данных . Впервые была предложена британским ученым-компьютерщиком Эдгаром Ф. Коддом как часть его реляционной модели .
Нормализация подразумевает организацию столбцов (атрибутов) и таблиц (отношений) базы данных для обеспечения того, чтобы их зависимости были надлежащим образом реализованы ограничениями целостности базы данных. Это достигается путем применения некоторых формальных правил либо с помощью процесса синтеза (создание нового проекта базы данных), либо декомпозиции (улучшение существующего проекта базы данных).
Цели
Основная цель первой нормальной формы, определенной Коддом в 1970 году, состояла в том, чтобы разрешить запрашивать и обрабатывать данные с использованием «универсального подъязыка данных», основанного на логике первого порядка . [1] Примером такого языка является SQL , хотя Кодд считал его имеющим серьезные недостатки. [2]
Цели нормализации за пределами 1NF (первой нормальной формы) были сформулированы Коддом следующим образом:
- Освободить коллекцию отношений от нежелательных зависимостей вставки, обновления и удаления.
- Уменьшить необходимость реструктуризации набора отношений по мере введения новых типов данных и тем самым увеличить срок службы прикладных программ.
- Сделать реляционную модель более информативной для пользователей.
- Сделать сбор отношений нейтральным по отношению к статистике запросов, поскольку эта статистика может меняться с течением времени.
— Э. Ф. Кодд, «Дальнейшая нормализация реляционной модели базы данных» [3]
{kind=link}
{kind=link}

{kind=link}

При попытке изменить (обновить, вставить или удалить) отношение в отношениях, которые не были достаточно нормализованы, могут возникнуть следующие нежелательные побочные эффекты:
- Аномалия вставки
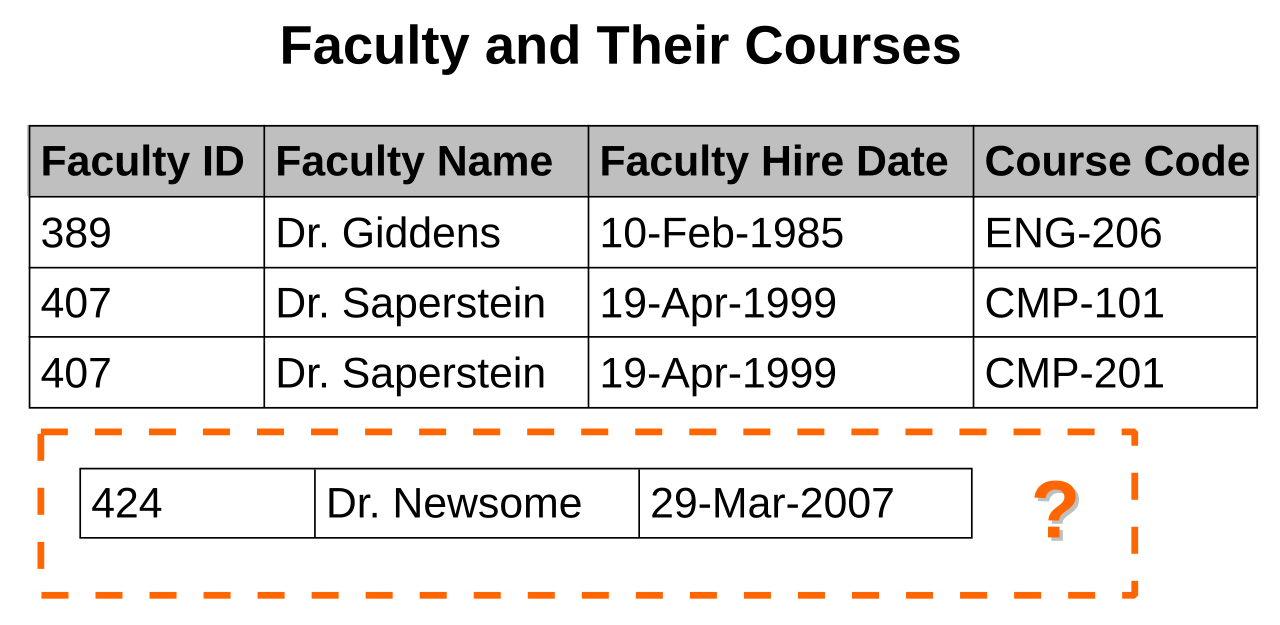
- Существуют обстоятельства, при которых некоторые факты вообще не могут быть записаны. Например, каждая запись в отношении «Преподавательский состав и их курсы» может содержать идентификатор факультета, название факультета, дату найма факультета и код курса. Таким образом, сведения о любом преподавателе, который преподает хотя бы один курс, могут быть записаны, но недавно нанятый преподаватель, который еще не был назначен преподавать какие-либо курсы, не может быть записан, за исключением установки кода курса на null .
- Обновление аномалии
- Одна и та же информация может быть выражена в нескольких строках; поэтому обновления отношения могут привести к логическим несоответствиям. Например, каждая запись в отношении «Навыки сотрудников» может содержать идентификатор сотрудника, адрес сотрудника и навык; таким образом, изменение адреса для конкретного сотрудника может потребоваться применить к нескольким записям (по одной для каждого навыка). Если обновление успешно только частично — адрес сотрудника обновлен в некоторых записях, но не в других — то отношение остается в несогласованном состоянии. В частности, отношение дает противоречивые ответы на вопрос о том, какой адрес у этого конкретного сотрудника.
- Аномалия удаления
- При определенных обстоятельствах удаление данных, представляющих определенные факты, требует удаления данных, представляющих совершенно другие факты. Отношение «Преподаватели и их курсы», описанное в предыдущем примере, страдает от этого типа аномалии, поскольку если преподаватель временно перестает быть назначенным на какие-либо курсы, последняя из записей, в которой появляется этот преподаватель, должна быть удалена, что фактически также удаляет преподавателя, если только поле «Код курса» не установлено на ноль.
Минимизируйте перепроектирование при расширении структуры базы данных
Полностью нормализованная база данных позволяет расширять ее структуру для размещения новых типов данных без слишком большого изменения существующей структуры. В результате приложения, взаимодействующие с базой данных, подвергаются минимальному влиянию.
Нормализованные отношения и отношения между одним нормализованным отношением и другим отражают реальные концепции и их взаимосвязи.
Нормальные формы
Кодд ввел концепцию нормализации и то, что сейчас известно как первая нормальная форма (1NF) в 1970 году. [4] Кодд продолжил определять вторую нормальную форму (2NF) и третью нормальную форму (3NF) в 1971 году, [5] а Кодд и Рэймонд Ф. Бойс определили нормальную форму Бойса–Кодда (BCNF) в 1974 году. [6]
Рональд Фейгин ввел четвертую нормальную форму (4NF) в 1977 году и пятую нормальную форму (5NF) в 1979 году. Кристофер Дж. Дейт ввел шестую нормальную форму (6NF) в 2003 году.
Неформально, отношение реляционной базы данных часто описывается как «нормализованное», если оно соответствует третьей нормальной форме. [7] Большинство отношений 3NF свободны от аномалий вставки, обновления и удаления.
Нормальные формы (от наименее нормализованной до наиболее нормализованной) следующие:
- UNF: Ненормализованная форма
- 1NF: Первая нормальная форма
- 2NF: Вторая нормальная форма
- 3NF: Третья нормальная форма
- EKNF: Элементарная ключевая нормальная форма
- BCNF: нормальная форма Бойса-Кодда
- 4NF: Четвертая нормальная форма
- ETNF: Основная нормальная форма кортежа
- 5NF: Пятая нормальная форма
- DKNF: нормальная форма доменного ключа
- 6NF: Шестая нормальная форма
| Ограничение (неформальное описание в скобках) | УНФ (1970) | 1NF (1970) | 2NF (1971) | 3NF (1971) | ЕКНФ (1982) | БКНФ (1974) | 4NF (1977) | ЕТНФ (2012) | 5NF (1979) | ДКНФ (1981) | 6NF (2003) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Уникальные строки (без повторяющихся записей) [4] |  |  | | | | | | | | | |
| Скалярные столбцы (столбцы не могут содержать отношения или составные значения) [5] |  | | | | | | | | | | |
| Каждый непервичный атрибут имеет полную функциональную зависимость от каждого потенциального ключа (атрибуты зависят от всего ключа) [5] | | | | | | | | | | | |
| Каждая нетривиальная функциональная зависимость либо начинается с суперключа , либо заканчивается первичным атрибутом (атрибуты зависят только от потенциальных ключей) [5] | | | | | | | | | | | |
| Каждая нетривиальная функциональная зависимость либо начинается с суперключа, либо заканчивается элементарным простым атрибутом (более строгая форма 3NF) | | | | | | | | | | | — |
| Каждая нетривиальная функциональная зависимость начинается с суперключа (более строгая форма 3NF) | | | | | | | | | | | — |
| Каждая нетривиальная многозначная зависимость начинается с суперключа | | | | | | | | | | | — |
| Каждая зависимость соединения имеет компонент суперключа [8] | | | | | | | | | | | — |
| Каждая зависимость соединения имеет только компоненты суперключа | | | | | | | | | | | — |
| Каждое ограничение является следствием ограничений домена и ключевых ограничений. | | | | | | | | | | | |
| Каждая зависимость соединения тривиальна | | | | | | | | | | | |
Пример пошаговой нормализации
Нормализация — это метод проектирования базы данных, который используется для проектирования таблицы реляционной базы данных до более высокой нормальной формы. [9] Процесс является прогрессивным, и более высокий уровень нормализации базы данных не может быть достигнут, если предыдущие уровни не были удовлетворены. [10]
Это означает, что, имея данные в ненормализованной форме (наименее нормализованной) и стремясь достичь наивысшего уровня нормализации, первым шагом будет обеспечение соответствия первой нормальной форме , вторым шагом будет обеспечение соответствия второй нормальной форме и так далее в указанном выше порядке, пока данные не будут соответствовать шестой нормальной форме .
Однако нормальные формы за пределами 4NF в основном представляют академический интерес, поскольку проблемы, для решения которых они предназначены, редко встречаются на практике. [11]
Данные в следующем примере были намеренно разработаны так, чтобы противоречить большинству нормальных форм. На практике часто можно пропустить некоторые шаги нормализации, поскольку данные уже нормализованы в некоторой степени. Исправление нарушения одной нормальной формы также часто исправляет нарушение более высокой нормальной формы. В примере для нормализации на каждом шаге была выбрана одна таблица, что означает, что в конце некоторые таблицы могут быть недостаточно нормализованы.
Исходные данные
Пусть существует таблица базы данных со следующей структурой: [10]
| Заголовок | Автор | Национальность автора | Формат | Цена | Предмет | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | американский | Твердый переплет | 49.99 |
| 520 | Толстый | Апресс | США | 1 | Учебник |
В этом примере предполагается, что у каждой книги только один автор.
Таблица, соответствующая реляционной модели, имеет первичный ключ , который однозначно идентифицирует строку. В нашем примере первичный ключ — это составной ключ { Title, Format} (обозначенный подчеркиванием):
| Заголовок | Автор | Национальность автора | Формат | Цена | Предмет | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | американский | Твердый переплет | 49.99 |
| 520 | Толстый | Апресс | США | 1 | Учебник |
Удовлетворение 1NF
В первой нормальной форме каждое поле содержит одно значение. Поле не может содержать набор значений или вложенную запись. Subject содержит набор значений Subject, что означает, что он не соответствует. Для решения проблемы субъекты извлекаются в отдельную таблицу Subject : [10]
| Заголовок | Автор | Национальность автора | Формат | Цена | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра |
|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | американский | Твердый переплет | 49.99 | 520 | Толстый | Апресс | США | 1 | Учебник |
| Заголовок | Имя субъекта |
|---|---|
| Начало проектирования и оптимизации базы данных MySQL | MySQL |
| Начало проектирования и оптимизации базы данных MySQL | База данных |
| Начало проектирования и оптимизации базы данных MySQL | Дизайн |
Вместо одной таблицы в ненормализованной форме теперь имеются две таблицы, соответствующие 1NF.
Удовлетворение 2NF
Напомним, что таблица Book ниже имеет составной ключ {Title, Format} , который не будет удовлетворять 2NF, если некоторое подмножество этого ключа является детерминантом. На этом этапе нашего дизайна ключ не финализирован как первичный ключ , поэтому он называется потенциальным ключом . Рассмотрим следующую таблицу:
| Заголовок | Формат | Автор | Национальность автора | Цена | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра |
|---|---|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Твердый переплет | Чад Рассел | американский | 49.99 | 520 | Толстый | Апресс | США | 1 | Учебник |
| Начало проектирования и оптимизации базы данных MySQL | Электронная книга | Чад Рассел | американский | 22.34 | 520 | Толстый | Апресс | США | 1 | Учебник |
| Реляционная модель управления базами данных: версия 2 | Электронная книга | ЭФКодд | британский | 13.88 | 538 | Толстый | Эддисон-Уэсли | США | 2 | Научно-популярная |
| Реляционная модель управления базами данных: версия 2 | Мягкая обложка | ЭФКодд | британский | 39.99 | 538 | Толстый | Эддисон-Уэсли | США | 2 | Научно-популярная |
Все атрибуты, которые не являются частью ключа-кандидата, зависят от Title , но только Price также зависит от Format . Чтобы соответствовать 2NF и удалить дубликаты, каждый атрибут, не являющийся атрибутом ключа-кандидата, должен зависеть от всего ключа-кандидата, а не только от его части.
Чтобы нормализовать эту таблицу, сделайте {Title} (простым) потенциальным ключом (первичным ключом), чтобы каждый атрибут, не являющийся потенциальным ключом, зависел от всего потенциального ключа, и удалите Price в отдельную таблицу, чтобы сохранить ее зависимость от Format :
| Заголовок | Автор | Национальность автора | Страницы | Толщина | Издатель | Страна издателя | Идентификатор жанра | Название жанра |
|---|---|---|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | американский | 520 | Толстый | Апресс | США | 1 | Учебник |
| Реляционная модель управления базами данных: версия 2 | ЭФКодд | британский | 538 | Толстый | Эддисон-Уэсли | США | 2 | Научно-популярная |
| Заголовок | Формат | Цена |
|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Твердый переплет | 49.99 |
| Начало проектирования и оптимизации базы данных MySQL | Электронная книга | 22.34 |
| Реляционная модель управления базами данных: версия 2 | Электронная книга | 13.88 |
| Реляционная модель управления базами данных: версия 2 | Мягкая обложка | 39.99 |
Теперь обе таблицы Book и Price соответствуют 2NF .
Удовлетворение 3NF
Таблица Book по-прежнему имеет транзитивную функциональную зависимость ({Author Nationality} зависит от {Author}, который зависит от {Title}). Аналогичные нарушения существуют для издателя ({Publisher Country} зависит от {Publisher}, который зависит от {Title}) и для жанра ({Genre Name} зависит от {Genre ID}, который зависит от {Title}). Следовательно, таблица Book не находится в 3NF. Чтобы решить эту проблему, мы можем поместить {Author Nationality}, {Publisher Country} и {Genre Name} в их собственные соответствующие таблицы, тем самым устранив транзитивные функциональные зависимости:
| Заголовок | Автор | Страницы | Толщина | Издатель | Идентификатор жанра |
|---|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | Чад Рассел | 520 | Толстый | Апресс | 1 |
| Реляционная модель управления базами данных: версия 2 | ЭФКодд | 538 | Толстый | Эддисон-Уэсли | 2 |
|
| Автор | Национальность автора |
|---|---|
| Чад Рассел | американский |
| ЭФКодд | британский |
| Издатель | Страна |
|---|---|
| Апресс | США |
| Эддисон-Уэсли | США |
| Идентификатор жанра | Имя |
|---|---|
| 1 | Учебник |
| 2 | Научно-популярная |
Удовлетворение EKNF
Нормальная форма элементарного ключа (EKNF) находится строго между 3NF и BCNF и нечасто обсуждается в литературе. Она предназначена для того, чтобы «охватить основные качества как 3NF, так и BCNF» , избегая при этом проблем обеих (а именно, что 3NF «слишком прощающая», а BCNF «склонна к вычислительной сложности»). Поскольку она редко упоминается в литературе, она не включена в этот пример.
Удовлетворение 4NF
Предположим, что база данных принадлежит франшизе книжного ритейлера, у которого есть несколько франчайзи, владеющих магазинами в разных местах. И поэтому ритейлер решил добавить таблицу, содержащую данные о наличии книг в разных местах:
| Идентификатор франчайзи | Заголовок | Расположение |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Флорида |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 1 | Реляционная модель управления базами данных: версия 2 | Калифорния |
| 1 | Реляционная модель управления базами данных: версия 2 | Флорида |
| 1 | Реляционная модель управления базами данных: версия 2 | Техас |
| 2 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 2 | Начало проектирования и оптимизации базы данных MySQL | Флорида |
| 2 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 2 | Реляционная модель управления базами данных: версия 2 | Калифорния |
| 2 | Реляционная модель управления базами данных: версия 2 | Флорида |
| 2 | Реляционная модель управления базами данных: версия 2 | Техас |
| 3 | Начало проектирования и оптимизации базы данных MySQL | Техас |
Поскольку эта структура таблицы состоит из составного первичного ключа , она не содержит никаких неключевых атрибутов и уже находится в BCNF (и, следовательно, также удовлетворяет всем предыдущим нормальным формам). Однако, предполагая, что все доступные книги предлагаются в каждой области, Title не привязан однозначно к определенному Location и, следовательно, таблица не удовлетворяет 4NF .
Это означает, что для удовлетворения четвертой нормальной формы эту таблицу также необходимо разложить:
|
|
Теперь каждая запись однозначно идентифицируется суперключом , поэтому 4NF выполняется.
Удовлетворительный ETNF
Предположим, что франчайзи также могут заказывать книги у разных поставщиков. Пусть отношение также подчиняется следующему ограничению:
- Если определенный поставщик поставляет определенное наименование
- и право собственности предоставляется франчайзи
- и франчайзи снабжается поставщиком ,
- затем поставщик предоставляет право собственности франчайзи . [ 12]
| Идентификатор поставщика | Заголовок | Идентификатор франчайзи |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | 1 |
| 2 | Реляционная модель управления базами данных: версия 2 | 2 |
| 3 | Изучение SQL | 3 |
Эта таблица находится в 4NF , но идентификатор поставщика равен соединению его проекций: {{Идентификатор поставщика, Название}, {Идентификатор франчайзи}, {Идентификатор франчайзи, идентификатор поставщика}}. Ни один компонент этой зависимости соединения не является суперключом (единственным суперключом является весь заголовок), поэтому таблица не удовлетворяет ETNF и может быть дополнительно разложена: [12]
|
|
|
Разложение обеспечивает соответствие ETNF.
Удовлетворение 5NF
Чтобы обнаружить таблицу, не удовлетворяющую 5NF , обычно необходимо тщательно изучить данные. Предположим, что таблица из примера 4NF с небольшим изменением данных и давайте проверим, удовлетворяет ли она 5NF :
| Идентификатор франчайзи | Заголовок | Расположение |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Изучение SQL | Калифорния |
| 1 | Реляционная модель управления базами данных: версия 2 | Техас |
| 2 | Реляционная модель управления базами данных: версия 2 | Калифорния |
Разложение этой таблицы снижает избыточность, в результате чего получаются следующие две таблицы:
|
|
Запрос, объединяющий эти таблицы, вернет следующие данные:
| Идентификатор франчайзи | Заголовок | Расположение |
|---|---|---|
| 1 | Начало проектирования и оптимизации базы данных MySQL | Калифорния |
| 1 | Изучение SQL | Калифорния |
| 1 | Реляционная модель управления базами данных: версия 2 | Калифорния |
| 1 | Реляционная модель управления базами данных: версия 2 | Техас |
| 1 | Изучение SQL | Техас |
| 1 | Начало проектирования и оптимизации базы данных MySQL | Техас |
| 2 | Реляционная модель управления базами данных: версия 2 | Калифорния |
JOIN возвращает на три строки больше, чем должно; добавление еще одной таблицы для уточнения связи приводит к получению трех отдельных таблиц:
|
|
|
Что теперь вернет JOIN? На самом деле, объединить эти три таблицы невозможно. Это означает, что невозможно было разложить Franchisee - Book - Location без потери данных, поэтому таблица уже удовлетворяет 5NF .
CJ Date утверждал, что только база данных в 5NF является по-настоящему «нормализованной». [13]
Удовлетворительный DKNF
Давайте посмотрим на таблицу Book из предыдущих примеров и посмотрим, удовлетворяет ли она доменно-ключевой нормальной форме :
| Заголовок | Страницы | Толщина | Идентификатор жанра | Идентификатор издателя |
|---|---|---|---|---|
| Начало проектирования и оптимизации базы данных MySQL | 520 | Толстый | 1 | 1 |
| Реляционная модель управления базами данных: версия 2 | 538 | Толстый | 2 | 2 |
| Изучение SQL | 338 | Стройный | 1 | 3 |
| Поваренная книга SQL | 636 | Толстый | 1 | 3 |
Логично, что Толщина определяется количеством страниц. Это значит, что она зависит от Pages , что не является ключом. Давайте приведем пример соглашения, согласно которому книга объемом до 350 страниц считается «тонкой», а книга объемом более 350 страниц считается «толстой».
Это соглашение технически является ограничением, но оно не является ни ограничением домена, ни ограничением ключа; поэтому мы не можем полагаться на ограничения домена и ограничения ключа для сохранения целостности данных.
Другими словами – ничто не мешает нам указать, например, «Толстая» для книги, в которой всего 50 страниц – и это сделает таблицу нарушающей ДКНФ .
Чтобы решить эту проблему, создается таблица, содержащая перечисление, определяющее толщину , и этот столбец удаляется из исходной таблицы:
|
|
Таким образом, нарушение целостности домена устранено, и таблица находится в DKNF .
Удовлетворение 6NF
Простое и интуитивно понятное определение шестой нормальной формы заключается в том, что «таблица находится в 6NF , когда строка содержит первичный ключ и не более одного другого атрибута» . [14]
Это означает, например, что таблица Publisher была разработана при создании 1NF:
| Идентификатор издателя | Имя | Страна |
|---|---|---|
| 1 | Апресс | США |
необходимо дополнительно разложить на две таблицы:
|
|
Очевидным недостатком 6NF является разрастание таблиц, необходимых для представления информации об одной сущности. Если таблица в 5NF имеет один столбец первичного ключа и N атрибутов, представление той же информации в 6NF потребует N таблиц; многополевые обновления одной концептуальной записи потребуют обновлений нескольких таблиц; а вставки и удаления аналогично потребуют операций по нескольким таблицам. По этой причине в базах данных, предназначенных для обслуживания потребностей онлайн-обработки транзакций (OLTP), 6NF не следует использовать.
Однако в хранилищах данных , которые не допускают интерактивных обновлений и которые специализированы для быстрых запросов к большим объемам данных, некоторые СУБД используют внутреннее представление 6NF, известное как столбчатое хранилище данных . В ситуациях, когда количество уникальных значений столбца намного меньше количества строк в таблице, столбчатое хранилище позволяет значительно экономить пространство за счет сжатия данных. Столбчатое хранилище также позволяет быстро выполнять запросы диапазона (например, показывать все записи, где определенный столбец находится между X и Y или меньше X.)
Однако во всех этих случаях разработчику базы данных не нужно вручную выполнять нормализацию 6NF, создавая отдельные таблицы. Некоторые СУБД, которые специализируются на хранении данных, такие как Sybase IQ , используют столбчатое хранилище по умолчанию, но разработчик все равно видит только одну многостолбцовую таблицу. Другие СУБД, такие как Microsoft SQL Server 2012 и более поздние версии, позволяют указать «индекс columnstore» для конкретной таблицы. [15]
Смотрите также
Примечания и ссылки
- ^ "Принятие реляционной модели данных... позволяет разработать универсальный подъязык данных, основанный на прикладном исчислении предикатов. Исчисления предикатов первого порядка достаточно, если набор отношений находится в нормальной форме. Такой язык предоставил бы мерило лингвистической мощности для всех других предлагаемых языков данных и сам по себе был бы сильным кандидатом на встраивание (с соответствующей синтаксической модификацией) в различные языки-носители (программирование, командно- или проблемно-ориентированные)". Кодд, "Реляционная модель данных для больших общих банков данных" Архивировано 12 июня 2007 г. в Wayback Machine , стр. 381
- ^ Кодд, Э.Ф. Глава 23, «Серьезные недостатки SQL», в книге «Реляционная модель управления базами данных: версия 2» . Addison-Wesley (1990), стр. 371–389
- ^ Кодд, ЭФ «Дальнейшая нормализация реляционной модели базы данных», стр. 34
- ^ ab Codd, EF (июнь 1970 г.). «Реляционная модель данных для больших общих банков данных». Communications of the ACM . 13 (6): 377–387 . doi : 10.1145/362384.362685 . S2CID 207549016.
- ^ abcd Codd, EF "Дальнейшая нормализация реляционной модели базы данных". (Представлено на симпозиуме по компьютерным наукам Courant Computer Science Symposia Series 6, "Системы баз данных", Нью-Йорк, 24–25 мая 1971 г.) IBM Research Report RJ909 (31 августа 1971 г.). Переиздано в Randall J. Rustin (ред.), Системы баз данных: симпозиумы по компьютерным наукам Courant Computer Science Symposia Series 6. Prentice-Hall, 1972.
- ^ Кодд, Э. Ф. "Недавние исследования систем реляционных баз данных". IBM Research Report RJ1385 (23 апреля 1974 г.). Переиздано в Proc. 1974 Congress (Стокгольм, Швеция, 1974 г.), Нью-Йорк: Северная Голландия (1974 г.).
- ^ Дейт, К.Дж. (1999). Введение в системы баз данных . Эддисон-Уэсли. стр. 290.
- ^ Дарвен, Хью; Дейт, К. Дж.; Фейгин, Рональд (2012). "Нормальная форма для предотвращения избыточных кортежей в реляционных базах данных" (PDF) . Труды 15-й Международной конференции по теории баз данных . Совместная конференция EDBT/ICDT 2012. Серия трудов Международной конференции ACM. Ассоциация вычислительной техники . стр. 114. doi :10.1145/2274576.2274589. ISBN 978-1-4503-0791-8. OCLC 802369023. Архивировано (PDF) из оригинала 6 марта 2016 г. Получено 22 мая 2018 г.
- ^ Кумар, Кунал; Азад, СК (октябрь 2017 г.). «Шаблон проектирования нормализации базы данных». 2017 г. 4-я Международная конференция IEEE Uttar Pradesh Section по электротехнике, компьютерам и электронике (UPCON) . IEEE. стр. 318–322 . doi :10.1109/upcon.2017.8251067. ISBN 9781538630044. S2CID 24491594.
- ^ abc "Нормализация базы данных в MySQL: четыре быстрых и простых шага". ComputerWeekly.com . Архивировано из оригинала 30 августа 2017 г. . Получено 23 марта 2021 г. .
- ^ "Нормализация базы данных: 5-я нормальная форма и далее". MariaDB KnowledgeBase . Получено 23 января 2019 г.
- ^ ab Date, CJ (21 декабря 2015 г.). Новый словарь реляционных баз данных: термины, концепции и примеры. "O'Reilly Media, Inc.". стр. 138. ISBN 9781491951699.
- ↑ Дата, CJ (21 декабря 2015 г.). Новый словарь реляционных баз данных: термины, концепции и примеры. "O'Reilly Media, Inc.". стр. 163. ISBN 9781491951699.
- ^ "нормализация - Хотелось бы понять 6NF на примере". Stack Overflow . Получено 23 января 2019 г. .
- ^ Корпорация Microsoft. Индексы Columnstore: Обзор. https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview . Доступ 23 марта 2020 г.
Дальнейшее чтение
- Дейт, К.Дж. (1999), Введение в системы баз данных (8-е изд.). Эддисон-Уэсли Лонгман. ISBN 0-321-19784-4 .
- Кент, В. (1983) Простое руководство по пяти нормальным формам в теории реляционных баз данных , Communications of the ACM, т. 26, стр. 120–125
- Х.-Дж. Шек, П. Пистор Структуры данных для интегрированной системы управления базами данных и поиска информации
Внешние ссылки
- Кент, Уильям (февраль 1983 г.). «Простое руководство по пяти нормальным формам в теории реляционных баз данных». Сообщения ACM . 26 (2): 120– 125. doi : 10.1145/358024.358054 . S2CID 9195704.
- Основы нормализации баз данных. Архивировано 5 февраля 2007 г. на Wayback Machine Майком Чапплом (About.com)
- Введение в нормализацию базы данных Архивировано 28 сентября 2011 г. на Wayback Machine , часть 2 Архивировано 8 июля 2011 г. на Wayback Machine
- Введение в нормализацию баз данных Майка Хиллера.
- Учебник по первым 3 нормальным формам от Фреда Коулсона
- Описание основ нормализации базы данных от Microsoft
- Нормализация в СУБД от Чайтаньи (beginnersbook.com)
- Пошаговое руководство по нормализации базы данных
- ETNF – Основная нормальная форма кортежа Архивировано 6 марта 2016 г. на Wayback Machine
